
Python map函数(类)详解
理论
map()函数是Python的内置函数,会根据提供的函数参数,对传入的序列数据进行映射。
所以,map()函数也称映射函数。
在Python中,map是一个类,有着迭代方法,能够返回对应值。平时也能充当着函数使用:
1 | print(list(map(lambda x:x[0],[[1,2],[3,4]]))) |
1 | data=[[1,2],[3,4]] |
格式
最常见的格式为:
1 | map(function,iterables,...)->map |
Input
- function: 映射函数
- iterables: 可迭代序列
Output
- 一个可迭代对象
实践
我们来进行一个简单的尝试!
实例一
设计一个函数,将两个数组A和B中的元素加起来。
1 | def Add(x,y): |
那如果对格式输入不那么严格,又想比较简便地实现操作,我们可以通过map+lambda表达式的方式,对输入的元素进行一一映射。
1 | print(list(map(lambda x,y:x+y,A,B))) |
此时,第一个参数是一个映射(函数),第二,第三个参数则是输入的可迭代对象。map会自动的依次取出可迭代对象中的每个元素,通过映射输出。我们可以通过map.__next__()控制获取每一个元素,或是直接将返回的迭代对象转化为list获取全部元素。
map能够确保数据的最小截断,也就是满足两个或多个可迭代对象进行的最小长度。比如上文提到的,A数组的长度是高于B数组的,但由于map对象的特性,返回值只保留到B的长度。
是不是学会了!那我们再来看一题。
将一个元组对象转化为一个列表。
1 | A=((7),(7),(7),(7),(7),(7),(7),(8)) |
实例二
出自LC417太平洋大西洋水流问题
有一个 m × n 的矩形岛屿,与 太平洋 和 大西洋 相邻。 “太平洋” 处于大陆的左边界和上边界,而 “大西洋” 处于大陆的右边界和下边界。
这个岛被分割成一个由若干方形单元格组成的网格。给定一个 m x n 的整数矩阵 heights , heights[r][c]表示坐标 (r, c) 上单元格 高于海平面的高度 。
岛上雨水较多,如果相邻单元格的高度 小于或等于 当前单元格的高度,雨水可以直接向北、南、东、西流向相邻单元格。水可以从海洋附近的任何单元格流入海洋。
返回网格坐标 result 的 2D 列表 ,其中 result[i] = [ri, ci] 表示雨水从单元格 (ri, ci) 流动 既可流向太平洋也可流向大西洋 。
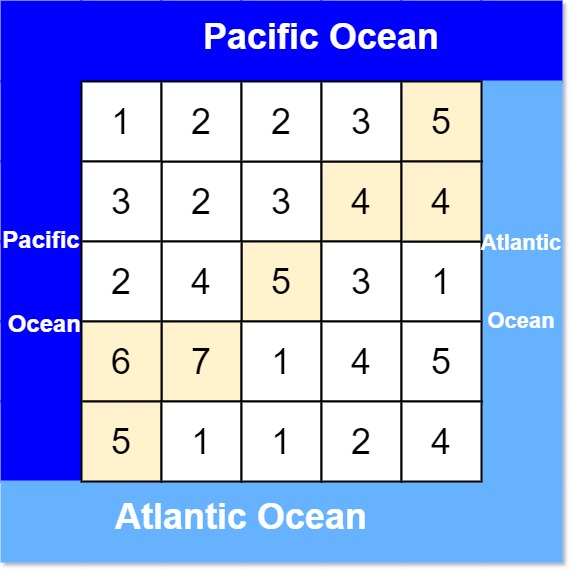
输入: heights = [[1,2,2,3,5],[3,2,3,4,4],[2,4,5,3,1],[6,7,1,4,5],[5,1,1,2,4]]
输出: [[0,4],[1,3],[1,4],[2,2],[3,0],[3,1],[4,0]]
1 | class Solution: |


